
目录
Explain命令及数据库优化
背景
一个查询课程计划的SQL语句,采用表的自连接方式进行查询 无索引
Explain 命令
查询所花费时间为0.089s

分析执行情况可看到 进行了全表扫描 type= ALL
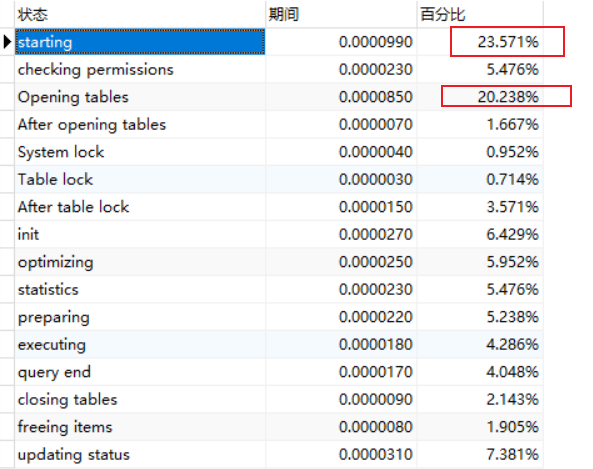
添加索引
-- alter table `table_name` add index `index_name`(colum);
alter table teachplan add index parent(parentid);
EXPLAIN
SELECT
a.id one_id,
a.pname one_pname,
b.id two_id,
b.pname two_pname,
c.id three_id,
c.pname three_pname
FROM
teachplan a
LEFT JOIN teachplan b
ON a.id = b.parentid
LEFT JOIN teachplan c
ON b.id = c.parentid
WHERE a.parentid = '0'
AND a.courseid = '402885816243d2dd016243f24c030002'
ORDER BY a.orderby,
b.orderby,
c.orderby
再次查询

执行时间为0.44s 且可见使用了parent索引 扫描的行数也减少为15
补充
ID
ID列中的数据为一组数字,表示执行 SELECT语句的顺序
ID值相同时,执行顺序由上至下
ID值越大优先级越高,越先被执行
SELECT_TYPE
查询类型,是单表查询、联合查询还是子查询等 可能会出现以下值
| 查询类型 | 说明 |
|---|---|
| SIMPLE | 简单的 select 查询,不使用 union 及子查询 |
| PRIMARY | 最外层的 select 查询(使用到主键作为查询条件) |
| UNION UNION | 中的第二个或随后的 select 查询,不 依赖于外部查询的结果集 |
| DEPENDENT UNION | UNION 中的第二个或随后的 select 查询,依 赖于外部查询的结果集 |
| SUBQUERY | 子查询中的第一个 select 查询,不依赖于外 部查询的结果集 |
| DEPENDENT SUBQUERY | 子查询中的第一个 select 查询,依赖于外部 查询的结果集 |
| DERIVED | 用于 from 子句里有子查询的情况。 MySQL 会 递归执行这些子查询, 把结果放在临时表里。 |
| UNCACHEABLE SUBQUERY | 结果集不能被缓存的子查询,必须重新为外 层查询的每一行进行评估。 |
| UNCACHEABLE UNION UNION | 中的第二个或随后的 select 查询,属 于不可缓存的子查询 |
TYPE
性能从高到低
| type | 说明 |
|---|---|
| system | 这是 const联接类型的一个特例当查询的表只有一行时使用 |
| const | 表中有且只有一个匹配的行时使用,如对主键或是唯一索引的查询这是效率最高的联接方式 |
| eq_ref | 唯一索引或主键查找,对于每个索引键,表中只有一条记录与之匹配 |
| ref | 连接不能基于关键字选择单个行,可能查找 到多个符合条件的行。 叫做 ref 是因为索引要 跟某个参考值相比较。这个参考值或者是一 个常数,或者是来自一个表里的多表查询的 结果值 |
| ref_or_null | 如同 ref, 但是 MySQL 必须在初次查找的结果 里找出 null 条目,然后进行二次查找。 |
| index_merge | 说明索引合并优化被使用了。 |
| unique_subquery | 在某些 IN 查询中使用此种类型,而不是常规的 ref:value IN (SELECT primary_key FROM single_table WHERE some_expr) |
| index_subquery | 在 某 些 IN 查 询 中 使 用 此 种 类 型 , 与 unique_subquery 类似,但是查询的是非唯一 性索引: value IN (SELECT key_column FROM single_table WHERE some_expr) |
| range | 只检索给定范围的行,使用一个索引来选择 行。key 列显示使用了哪个索引。当使用=、 <>、>、>=、<、<=、IS NULL、<=>、BETWEEN 或者 IN 操作符,用常量比较关键字列时,可 以使用 range。 |
| index | 全表扫描,只是扫描表的时候按照索引次序 进行而不是行。主要优点就是避免了排序, 但是开销仍然非常大。 |
| all | 最坏的情况,从头到尾全表扫描 |
5. prossible_keys:能在该表中使用哪些索引有助于查询
6. key:实际使用的索引
7. key_len:索引的长度,在不损失精确性的情况 下,长度越短越好
8. ref:索引的哪一列被使用了
9. rows:MySQL通过索引统计信息,`估算的所需读取的行数`,统计信息
Extra:
| 值 | 含义 |
|---|---|
| Distinct | 优化 distinct操作,在找到第一匹配的元组后即停止找同样值的动作 |
| Not exists | 使用 not exists来优化查询 |
| Using fileSort | 使用额外操作进行排序,通常会出现在 order b或 group by查询中 |
| Using index | 使用了覆盖索引进行查询 |
| Using temporary | MySQL需要使用临时表来处理查询,常见于排序,子查询,和分组查询 |
| Using where | 需要在 MySQL服务器层使用 WHERE条件来过滤数据 |
| select tables optimized away | 直接通过索引来获得数据,不用访问表 |
例子
通过Explain对分页语句进行优化
CREATE TABLE `product_comment` (
`comment_id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '评论ID',
`product_id` int(10) unsigned NOT NULL COMMENT '商品ID',
`order_id` bigint(20) unsigned NOT NULL COMMENT '订单ID',
`customer_id` int(10) unsigned NOT NULL COMMENT '用户ID',
`title` varchar(50) NOT NULL COMMENT '评论标题',
`content` varchar(300) NOT NULL COMMENT '评论内容',
`audit_status` tinyint(4) NOT NULL COMMENT '审核状态:0未审核1已审核',
`audit_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '评论时间',
`modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间',
PRIMARY KEY (`comment_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品评论表';
-- 一个分页查询 进行优化
SELECT
customer_id
,title
,content
FROM product_comment
WHERE audit status = 1 AND product id=199726
Limit 0,5
通过Explain执行情况发现,没有添加索引,于是可以添加索引进行优化
-- 通过区分度进行查询
SELECT COUNT(DISTINCT audit_status) / COUNT(*)
AS audit_rate
COUNT(DISTINCT product_id) / COUNT(*)
AS product_rate
FROM product_comment;
SELECT t.customer id, t.title, t content
FROM
(SELECT comment_id
FROM product_comment
WHERE product_id=199727 AND audit status=1 LIMIT 0, 15
)a JOIN product_comment t
ON a.comment_id =t.comment_id;
如何删除重复数据
删除评论表中对同一订单同一商品的重复评论,只保留最早的一条
- 查看是否存在对于一订单同一商品的重复评论
- 备份 product comment表
CREATE TABLE bak_product_comment_191022
AS SELECT * FROM product_comment
- 删除同一订单的重复评论
数据库备份
逻辑备份和物理备份
- 逻辑备份的结果为SQL语句适合于所有存储引擎
- 物理备份是对数据库目录的拷贝,对于内存表只备份
结构
使用mysqldump备份
-- 备份库
mysqldump 【OPTIONS】 database【tables】
-- 备份表
mysqldump 【OPTIONS】--databases 【OPTIONS】 DB1 【DB2】
-- 备份全库
mysqldump 【OPTIONS】--all-databases 【OPTIONS】
实操
create user 'backup'@'localhost' identified by 123456;
grant select, reload, lock tables, replication client, show view, event, process on *.* to 'backup'@'localhost';
-- 进行全库备份 【root#node】#
mysqldump -ubackup -p --master-data=2 --signle-transaction --routines --triggers --events
mc_orderdb > mc_orderdb.sql
-- 进行单表备份
mysqldump -ubackup -p --master-data = 2 --single-transaction --routines --triggers --events mc_orderdb order_master> order_master.sql
-- 进行全量备份
mysqldump -ubackup -p --master-data = 2 -- single-transaction --routines --triggers --events
--all-databases > mc.sql
-- 进行写库
grant file on *.* to 'backup'@'localhost'
mysqldump -ubackup -p --master-data = 2 --single-transaction --routines --triggers --events
--tab="/tmp/mc_orderdb" mc_orderdb
-- 特定范围备份 选择order_id 在 1000 和 1050之间的
mysqldump -ubackup -p --master-data = 2 --single-transaction --routines --where "order_id > 1000 and order_id < 1050" mc_orderdb order_master > order_master_1000.sql
恢复mysqldump备份的数据库
-- 客户端下的
mysql -u -p dbname < backup.sql
-- mysql命令行下
mysql > source/tmp/backup.sql
恢复误删除的数据
通过备份库与被删除库进行left join得到删除了的数据,即可恢复
参考:
http://www.shixinke.com/mysql/mysql-sql-optimization-with-using-explain-and-show-profile
