
目录
一致性算法–Paxos
概念介绍
一致性
对于一个分布式系统,不能同时满足以下三点: 一致性( consistency) 可用性( Availability) 分区容错性( Partition Tolerance)
最终一致性: 分布式系统刚写完 你立即读是读不到更改的 但保证最终能读到
一致性模型
- 最终一致性
- DNS(Domain Name System)
- Gossip( Cassandra的通信协议)
- 强一致性
- 同步
- Paxos
- Raft(multi-paxos)
- ZAB(multi-paxos)
分布式系统对容错性的解决方案是状态机复制
Paxos是一种共识算法 需要达成需要达成共识,还会取决于client的行为
强一致算法
同步(主从同步)
- Master接受写请求
- Master复制日志至 slave
- Master等待,直到所有的从库返回
一个slave节点失败, 或者Master阻塞,导致整个集群不可用,保证了一致性,可用性却大大降低
多数派
要求写都保证写入大于N/2个节点,每次读保证从大于N/2个节点中读 但在并发环境中 难以保证系统正确性
Paxos
Basic Paxos
角色:
- Client:系统外部角色,请求发起者。像民众。
- Propser:接受 Client请求,向集群提出提议( propose)。并在冲突发生时,起到冲突调节的作用。像议员,替民众提出议案。
- Accpetor( Voter):提议投票和接收者,只有在形成法定人数( Quorum,一般即为majority多数派)时,提议会最终被接受。像国会。
- Learner:提议接受者, backup,备份,对集群一致性没什么影响。像记录员
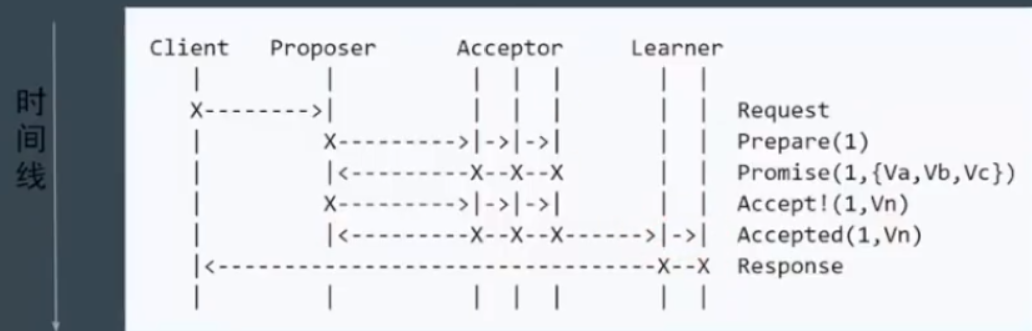
步骤:
- Prepare: 议员提出一个提案,编号为N,此N大于这个议员之前提出提案编号。请求 国会的 多数派接受
- Promise: 如果N大于此国会之前接受的任何提案编号则接受,否则拒绝
- Accpet: 达到了多数派,议员会发出 accept请求,此请求包含提案编号N,以及提案内容
- Accpeted: 若此国会在此期间没有收到任何编号大于N的提案,则接受此提案内容,否则忽略
流程:
可能出现
- 部分节点失败,但达到了 Quorums情况 即Acceptor 少了 一个
- Proposer失败 这时候会出现第二个Proposer 继续请求
- 活锁/决斗: 即议员A提出方案1 其他议员还没接收 议员B提出方案2 议员A不爽 不换内容 就该编号方案3 B方案4
小结:
Basic Paxos: 难实现、效率低(2轮RPC)、活锁
Multi Paxos
相比Basic Paxos出现新概念, Leader:唯一的 propser,所有请求都需经过此 Leader
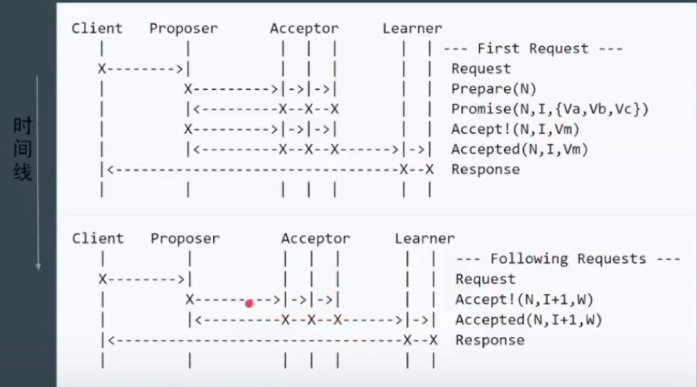
唯一一个议员 leader
Accept!(N, I, Vm): 第N任leader 提出第I个议案 内容为Vm
进一步简化
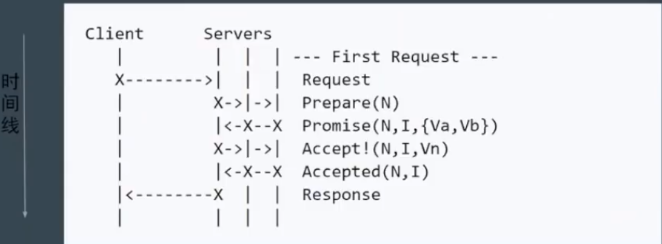
Servers中的第一个server想成为N任master 其他集群同意 则第一个成为master
Raft
划分成三个子问题:
- Leader election
- Log Replication
- Safety
重定义角色:
- Leader
- Follower
- Candidate
Raft中一个结点可能有3个角色 但整个集群有一个Leader Leader确定了大多数follower设置好了值 自己才会提交 将日志写入文件系统
刚开始的时候 没有leader 每个节点有个timeout 当timeout走完还没有leader 则自己会将自己作为cand请求其他节点希望同意自己成为leader 成为了leader 会进行发送心跳包 心跳包包含心跳和数据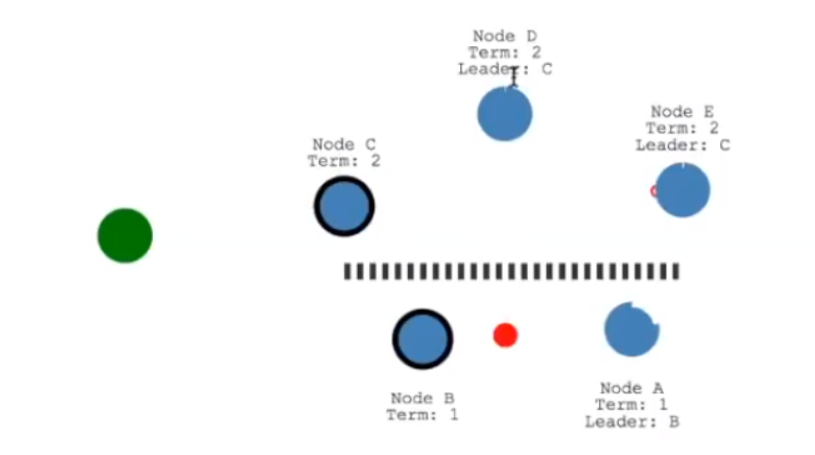
上图是进行了分区 分区了的话 就在分区的地方进行leader的竞选 但下半部的分区是无法写入日志的 因为没有满足多数派条件 分区恢复则少数服从多数
一致性并不一定代表完全正确性! 三个可能结果:成功,失败, unknown
ZAB
基本与raft相同。 在一些名词的叫法上有些区别:如ZAB将某一个 eader的周期称为epoh,而raft则称之为term
实现上也有些许不同:如raft保证日志连续性,心跳方向为 leader至 follower.ZAB则相反
